炸锅!斯坦福AI团队,被曝抄袭中国大模型!各方最新回应
斯坦福AI团队抄袭清华系大模型一事,在AI圈炸开了锅。
事件起因是5月29 日,一个由斯坦福学生组成的AI团队发布了一篇名为《Llama 3-V: Matching GPT4-V with a 100x smaller model and 500 dollars》的文章,称训练出了一个开源多模态模型Llama 3-V。这一模型比 GPT-4、Gemini Ultra、Claude Opus 等模型能力更强,而且训练成本只需要500美元。
Llama 3-V模型的团队成员 Aksh Garg 在社交平台X上发帖介绍了这一模型。该帖很快阅读量便超过30万,Llama 3-V 也很快冲上了全球知名开源社区HuggingFace的趋势榜首页。
随后,有热心网友发现,Llama 3-V与清华系大模型创业公司面壁智能的MiniCPM-Llama3-V 2.5在模型结构、代码、配置文件等方面几乎一模一样,只是斯坦福AI团队将其中的变量名称做了更改。该网友更是直接将相关的关键证据一一截图,进行列举证明。
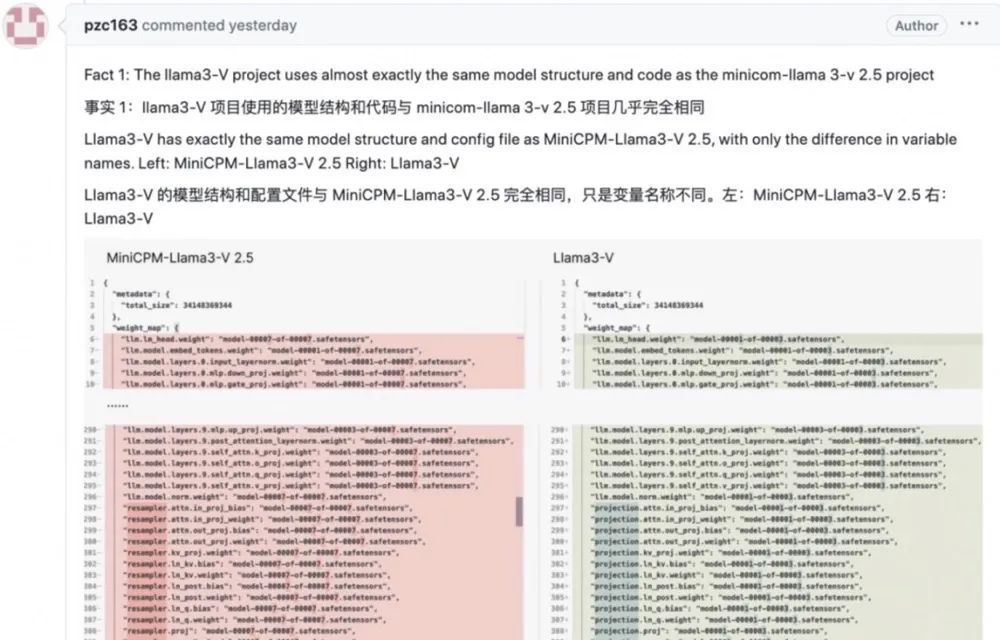
简言之,Llama3-V疑似套壳抄袭了面壁智能的MiniCPM-Llama3-V 2.5。发现了这一问题的网友在Llama3-V页面上提出了质疑,但Llama3-V页面很快就被作者删除了。目前,Llama3-V 的GitHub项目主页已显示为“404”,HuggingFace上的Llama3-V项目已不可见。作者社交媒体账号上,此前宣传Llama3-V的内容页已经遭到删除。
6月3日,Aksh Garg在其社交平台上发文回应了质疑,他艾特另外两名成员Siddharth Sharma和Mustafa Aljadery,并表示:“我和Siddharth都忙于自己的全职工作,所以Mustafa为该项目编写了所有代码。我俩都对多模态模型感到非常兴奋,并且喜欢他向我们描述的架构扩展,所以我们帮助他推广该产品。”他还进一步表示:“在看到这些(抄袭)指控后,我们与Mustafa讨论了Llama3-V的原创性证明,并要求提供训练代码,但到目前为止还没有看到任何证据。我们向原作者道歉,也对自己没有尽职尽责地验证其作品的原创性感到非常失望。”
公开资料显示,Siddharth Sharma与Aksh Garg都是斯坦福大学计算机系的本科生,发表过数篇机器学习相关的论文。Siddharth Sharma曾在亚马逊实习过一段时间,目前主要从事与AI和数据相关工作。Aksh Garg 则在SpaceX、斯坦福大学和加州理工学校等知名企业机构都实习过。Aksh Garg 所说的“编写了所有代码”的Mustafa Aljadery则就读于南加州大学,目前其社交平台X 账号已被设为隐私状态。
值得注意的是,斯坦福 AI 实验室主任 Christopher David Manning 在社交平台发帖谴责了抄袭行为,同时还对清华的开源模型表达了赞赏。
这一事件中的另外一个主角面壁智能也进行了公开回应。面壁智能CEO李大海在其朋友圈中发文表示:“技术创新不易,每一项工作都是团队夜以继日的奋斗结果,也是以有限算力对全世界技术进步与创新发展作出的真诚奉献。我们希望团队的好工作被更多人关注与认可,但不是以这种方式。我们对这件事深表遗憾!一方面感慨这也是一种受到国际团队认可的方式,另一方面也呼吁大家共建开放、合作、有信任的社区环境。一起加油合作,让世界因AGI的到来变得更好。”
公开资料显示,面壁智能成立于2022年8月,专注于大模型技术创新与应用转化。创始团队主要来自于清华大学自然语言处理实验室(THUNLP),公司CEO李大海是知乎首席技术官(CTO),联合创始人刘知远是清华大学计算机系副教授、博士生导师。
天眼查显示,面壁智能目前已完成两轮融资。去年4月,公司完成由知乎、智谱AI投资的数千万人民币天使轮融资;今年4月,公司宣布完成新一轮数亿元融资,由春华创投、华为哈勃领投,北京市人工智能产业投资基金等跟投,知乎作为战略股东持续跟投支持。
值得注意的是,李大海曾表示面壁智能是他作为知乎CTO发起的唯一一个项目。作为中等梯队的互联网上市企业,知乎面对全新的技术浪潮,想要热情拥抱,又无法如创业公司一样全情投入其中,于是选中面壁智能,作为AI大模型浪潮中对知乎技术力量的补充。而知乎所掌握大量中文互联网优质语料,也为面壁智能开展大模型训练提供了丰富的数据。
去年4月,知乎与面壁智能宣布联合研发的首个中文大模型“知海图AI”和应用“热榜摘要”正式面世。除此以外,双方在面壁智能研发的中文基座大模型CPM-Bee10b、对话类模型产品“面壁露卡”,以及内测第二款知乎场景下的模型应用“搜索聚合”等方面,也开展了广泛深入的合作。



